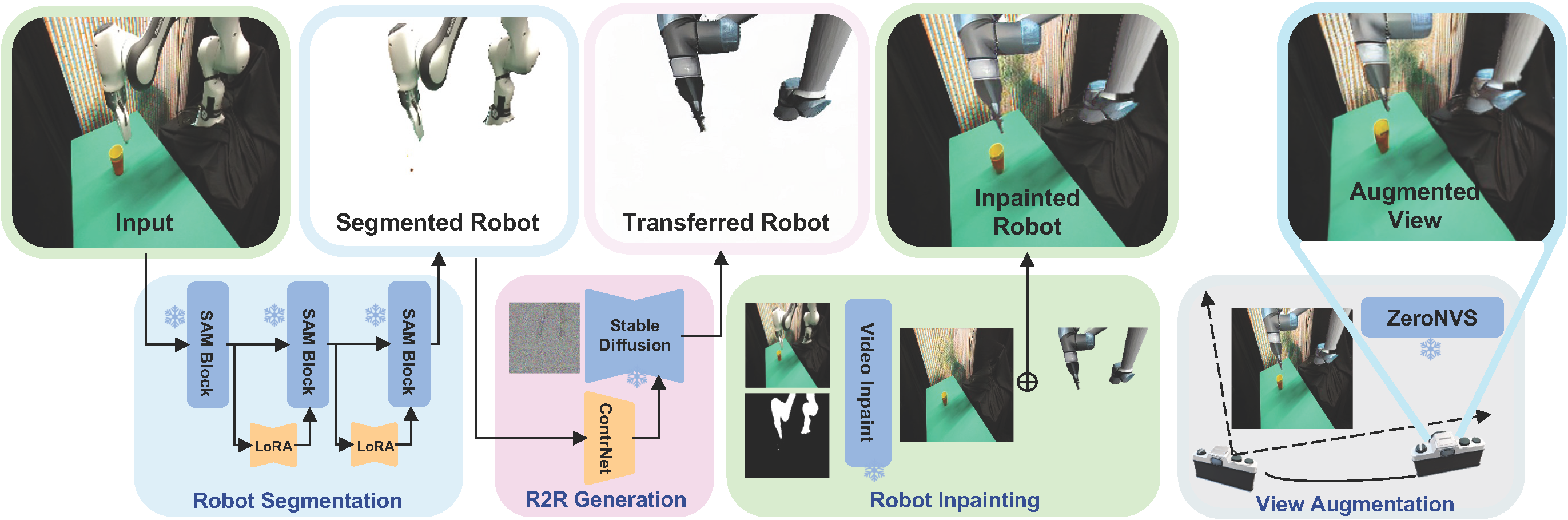
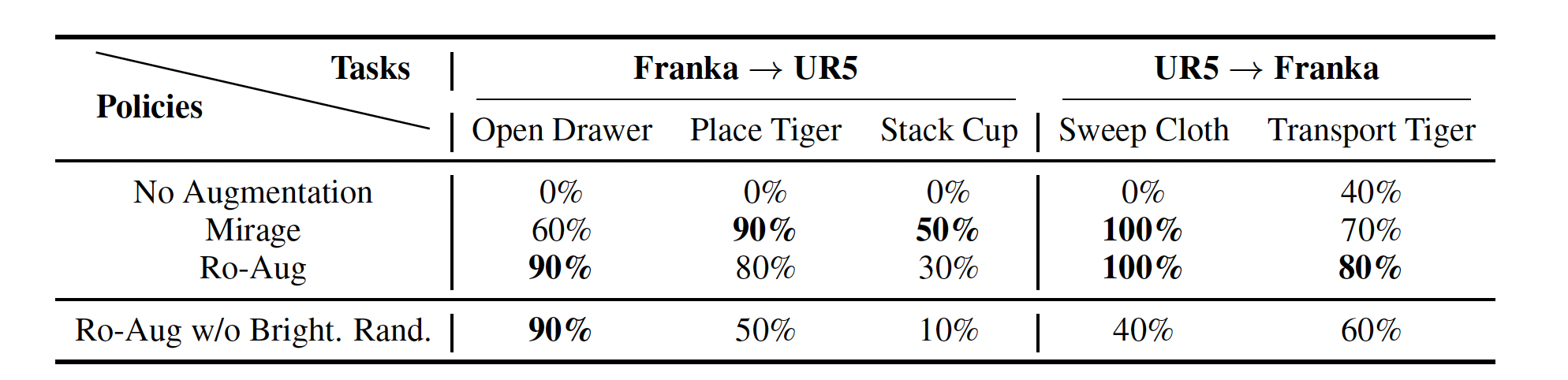
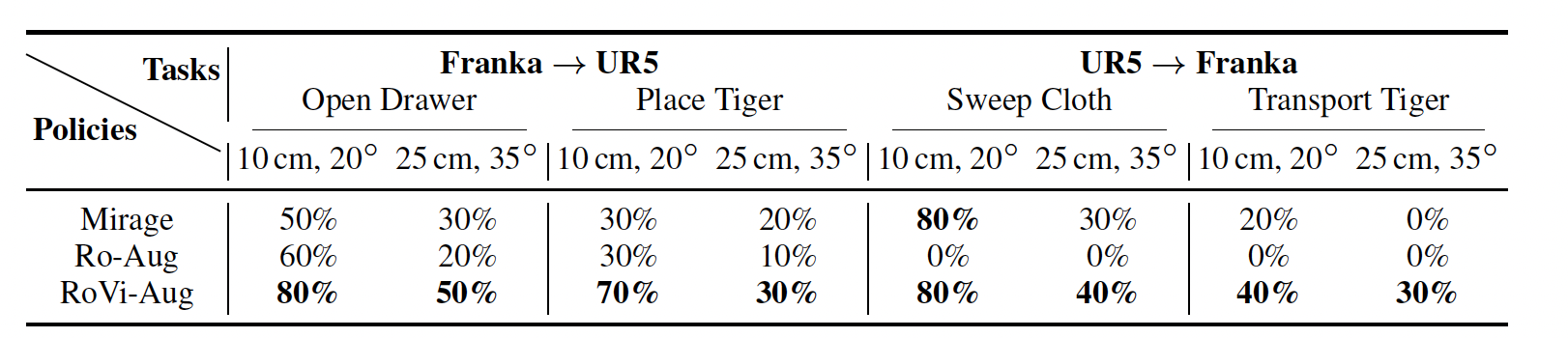
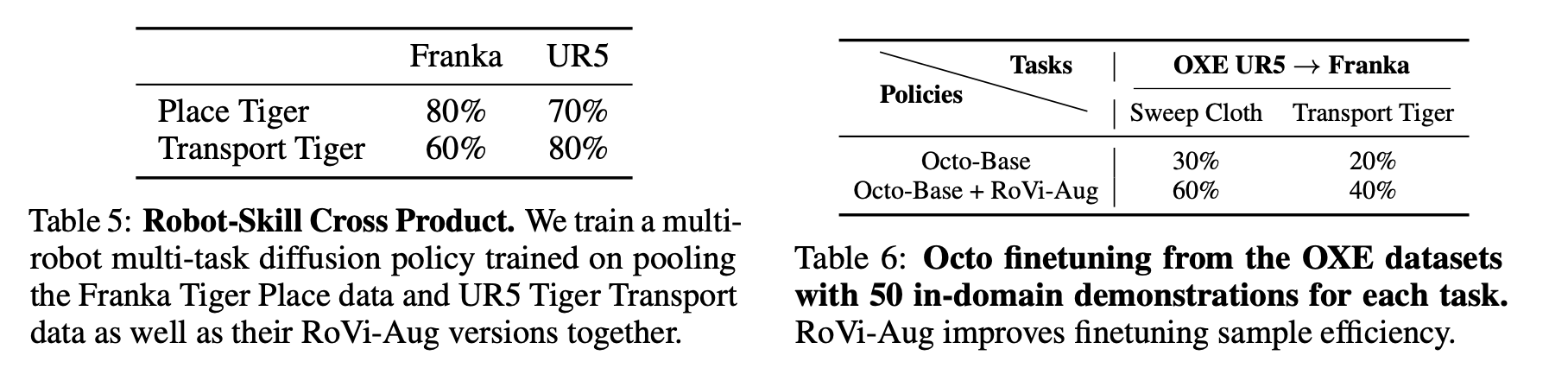
We study cross-embodiment transfer for vision-based policies without known camera poses and robot configurations. Given robot images (left), RoVi-Aug uses state-of-the-art diffusion models to augment the data and generate synthetic images with different robots and viewpoints (right). RoVi-Aug can zero-shot deploy on a different robot with significantly different camera angles and enable transfer between robots and skills via multi-robot multi-task learning.